RevAI Prototype
What i think must be spec sheet for a project of a machine learning assistant for binary reverse engineering.
Database
The data you need to have something interesting are source codes. If you want stuff to run on actual reversing software, source in C to have less work for your model to make the link between source and pseudo-C (and also you could perform the same kind of embedding / tokenization)
You need to have various :
- Size
- Usecase
- Compilation
- Obfuscation
One of the biggest mistake i made was keeping only the project which fitted in one C file, a real system must be able to study gigantic project with complexe structure.
Use old opensource project
This code may note have to much change in there purpose but have been patched many time for bug / vulnerability. Having the same project but different version will be very useful for purpose and author characterisation and vulnerability detection.
Use known vulnerable code
I think it could be hard to implement but very useful to have a system able to artificially put vulnerability from databases like diversevul to test and train vulnerability detection system without being to impacted by the full project context.
Model
Characterisation
The most important is to start from embedding system like SAFE which is already able to perform subroutine classification (purpose, author, vuln) by assigning a vector in an N-Dimensionnal space. I think we may have more information for this kind of embedding if we had DFG and CFG for graph embedding and also use SotA system for function and variable naming problematics.
The extraction of data may look like this :
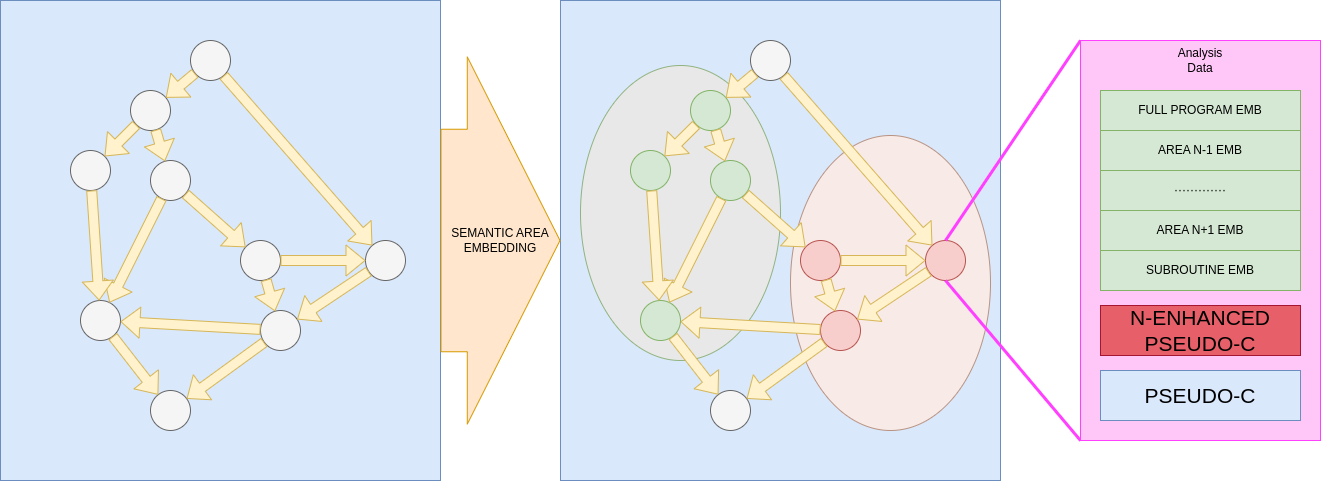
You get the call-graph from your analysis tool (IDA,Ghidra, Radare 2 …). For each function you will embed them in a N-dimensionnal space able to performing purpose classification. Then you will form small purpose groups and build an “average” embedding and repeat and reapeat … until making a whole program embedding.
Then your model need to have more information on the pseudo-C, so it could be good to do something like ProRec and add autogenerated structural info on the pseudo-C (may be enhanced by contextual embedding)
Training
As far as i know, Current LLM are RNN on steroid. We should keep a system like this but adding the context in the process :
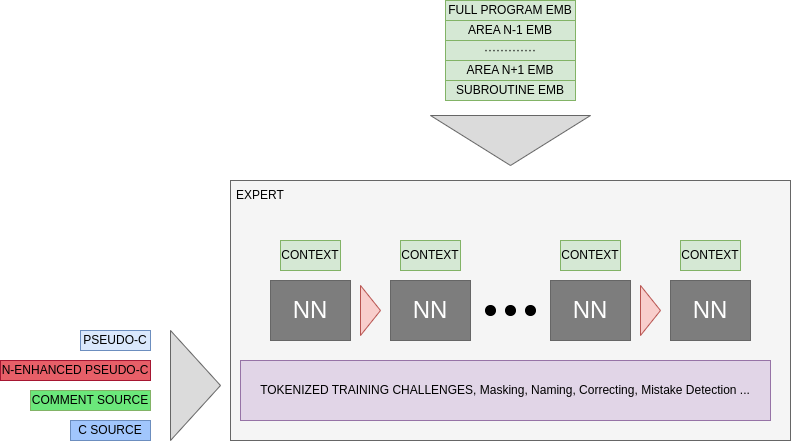
It won’t work in what i inderstant of a Transformer, the problem is that the embedding of the token HAVE to be fully separated from the tokenized code reading and guessing. The goal is to mimic the expert who worked on the code for a long time and remember what he had seen. so is able to easily recognise in context function.
Expert building
After all of that we have a model trained to predict the link between source and pseudo-C we need to solve real problem. To do that we can finetune the model kinda like what AIDAPAL did.
We can try to train it to do like AIDAPAL, but it’s also possible to train it to find vulnerability, trying to guess the author of a code, O-to-O similarity (OVERKILL system but may be is after lighter system to have finer result), patch detection …
Recap
Challenges
1- Various DB
2- Multiscale embedding
3- Context-Transformer
4- Good Labelled Expert DB
I think that just the “perfect embedding” may be a great tool for direct purpose classification, vuln detection and patch verification. The BERT good only if we want to automatise report and add an assistant for newbies.
Usecases
- Vuln detection
- 0-day finding
- Decompilation Enhancer
- C to higher level translation
- Patch verification
Important
The big problem of this stuff is the random aspect, and even if we had the most perfect system possible with 99.99999% accuracy in any of this task, the field where reverse is useful are critical so the harder is to convince the company/government that they can trust your system.