Source: https://arxiv.org/pdf/2501.04811v1
Date: 8 January 2025
Organisation(s): Carnegie Mellon University, USA
Author(s): L. DRAMKO, C. LE GOUES, E J. SCHWARTZ
Note: I'm really not sur of myself on this one, too much maths
[Paper Short] CODEALIGN
TLDR
A proposition of heuristic to test neural decompilation and/or train decompilation model, based on SSA representation to avoid syntax biaises in comparison.
Looks promising but the performance may not be good enough for real world training but i think it’s at least a good precision evaluation system.
Goal
Having a way to determine the quality of a decompilation model which is more detailed than BLEU or codeBERT score. It have to be able to tell which kind of operation are better recover and which kind not without depending on pure word comparison, just in term of logic comparison.
How
I will try to explain it with an real world example i had with LLM4Decompile V1.5.
First the program will get the SSA form of the codes.
Original C and SSA
void inefficientList(void) {
int tab[3];
tab[0] = 1;
tab[1] = 2;
tab[2] = 3;
for (int i = 0; i < 3; i++) {
printf("%i\n", tab[i]);
}
}
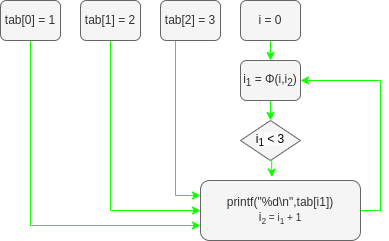
Decompiled C and SSA
void inefficientList() {
int a[] = {1, 2, 3};
for (int i = 0; i < 3; i++) {
printf("%i\n", a[i]);
}
}
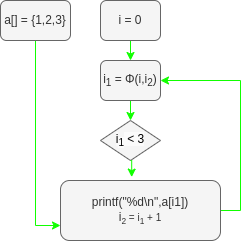
Then from the 2 SSA we will take the predifined var and constant of the program and draw their paths through the different operand and function.
Which give the same result for the 2 version.
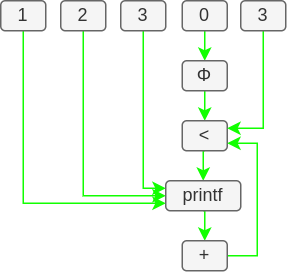
It mean that even if one do a 3 steps assignation of value in the tab and the other one a 1 step assignation we still have the same SSA representation so they must have the same purpose. Also this representation have no link with variable naming so the metric won’t be biaised by that.
More
My exemple doesn’t allow that but the paper also purpose way to test some hypothesis and distinct different level of truth of the different operand. Which may be used for scoring system, i let you check there example but i didn’t wanted to be too complex.
How reliable
Well i’m not able to go far into the mathematics but in term of similarity metric it look very interesting. They implemented a progressive checking system to test hypothesis and inherit the result of this test to the dependent element which give an even more precise result.
In theory it’s a good system but we may face a problem for model training
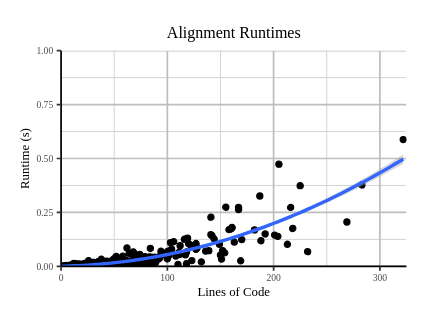
As you can see past 200 line of code there is a 50/50 chance to go over a quarter of a second to get the alignement.
So, it’s good enough for testing but not for training i think.
Conclusion
From the result they show it look it’s a very goog system de really check the logic similarity of 2 code without being biaised by correct naming.
If we want to use it for training it may need a little of simplification so it could run faster, but i think it make break the precision of the evaluation.
Another usecase that i think about maybe be to use the alignement as an additionnal contextual information for a model using an high context system.