Source: https://arxiv.org/pdf/2410.18561
Date: 24 October 2024
Organisation(s): University of Science and Technology of China
Author(s): X SHANG, L HU, S CHENG, G CHEN, B WU, W ZHANG, N YU
Note: I readed it a long time ago but a recruiter asked me to do a paper synthesis so here we go
[Paper Short] IRBinDiff
TLDR
A good system for binary comparison using LLVM-IR and SoTa strategy to get a good embedding of subroutines and full program using BERT and GCNN. It’s test in One to One and one to Many and also test the impact of the different strategy on the accuracy of the system.
Goal
To get a system that’s able to do binary comparison which perform better than similar alternatives in cross-compiler, cross-optimisation and cross-architecture. So they want an embedding able to get an high level representation of the program, like a semantic signature but better.
How
1 Get clean Data
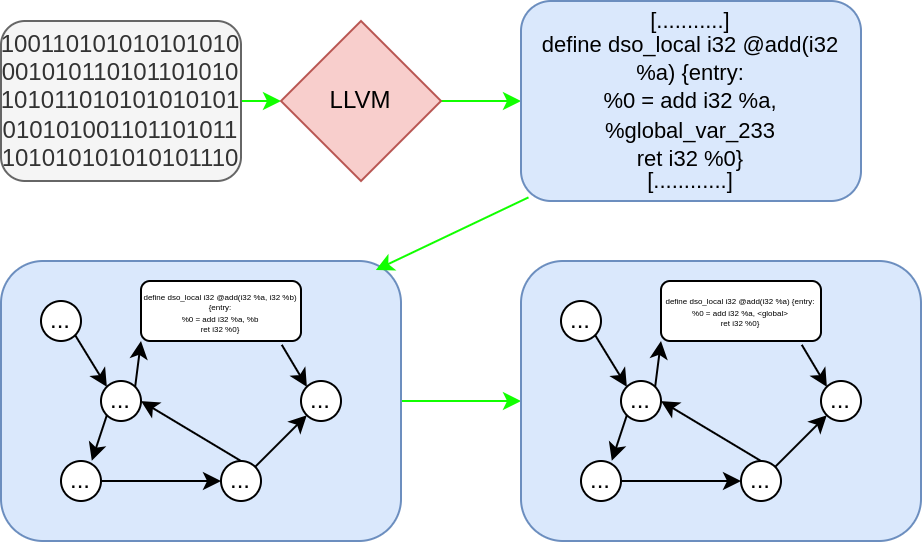
- Pass the binary through LLVM to get there IR (I think that’s good, a tool like LLVM can be use for deobfuscation and code isomorphism for simplification)
- Extract the CFG with the LLVM IR code in the basic block
- Simplify the basic block content to limitat useless noise (var name and type simplification)
2 The models
BERT
It’s a standard BERT trained with masking and next sequence prediction. The little tricky difference is the tokenizer which is specialised for this usecase. The goal of the BERT is to embed the content of the basic block, normalize or not.
GCNN
A GCNN train through contrastive learning. It take the embedding from on node and from the node around him to get a better representation of the context. As far as i seen in my looong(6 months) carriere is that a big problem of usage of NLP technique for binary analysis is the context size. And this strategy is kinda smart and may minimise the problem.
Results
note on performance
The system has been trained on a heavy system with 10 ~2k€ GPU and a 48 core CPU. It’s small compared to what we can see for LLM training but we are on a very specific usecase. I’d like to have more information on the performance on real world usage.
One to One
They tested the performance with balance pair set (10k positive / 10k negative) and unbalanced pair set (2k positive / 200k negative).
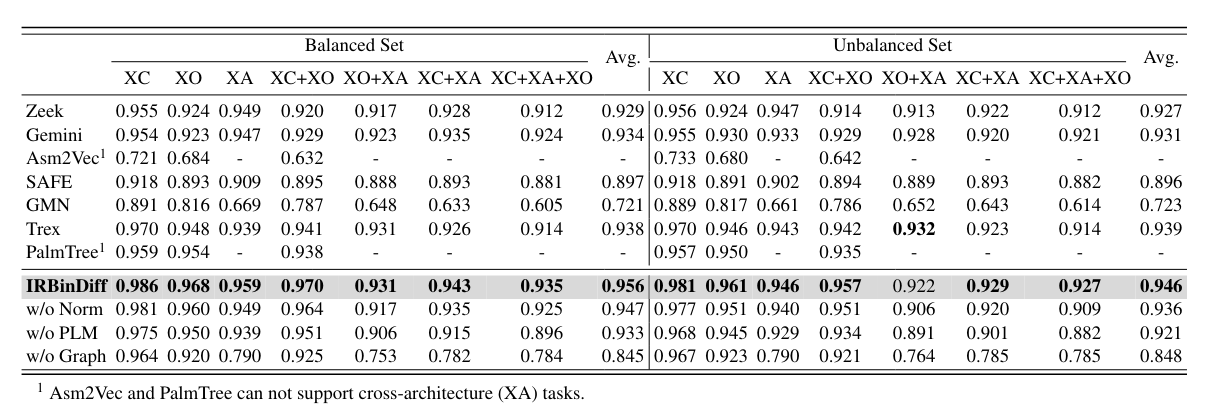
as we can see we have similar performance as Trex, Zeek and Gemini (slightly better but not that significant without more test)
good enough for state of the art, can be a usefull tool to faster the task of reverse engineer.
One to Many
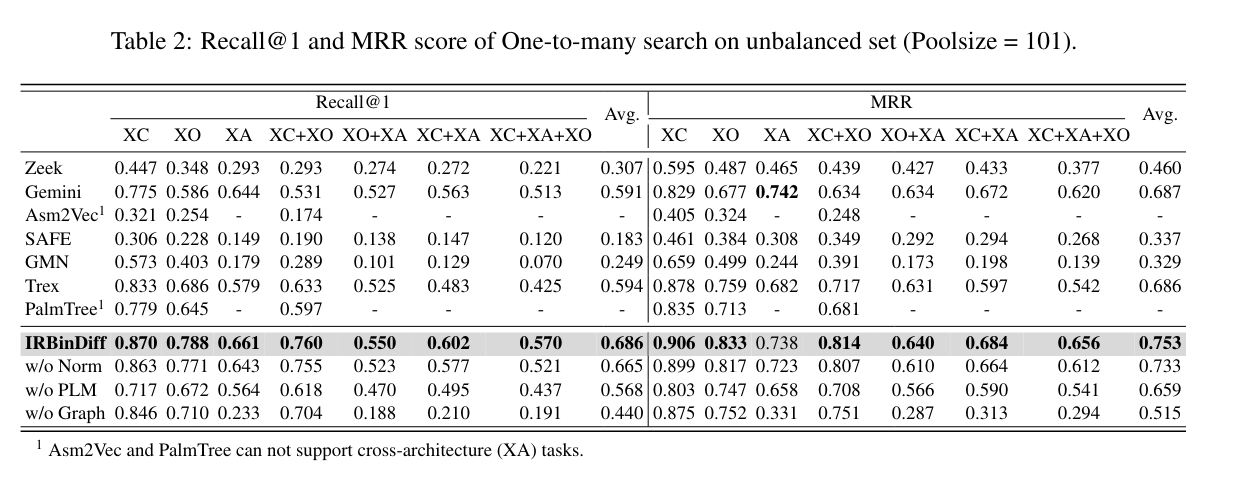
Now the only that can really follow IRBinDiff are Gemini and Trex but when there is optimisation in the equation IRBindiff perform slightly better.
More
What is very interesting in this paper is that in the bench it show the impact on removal of some component of the system so we can see that the the more important element are Pretrained Model > Graph neighbor > Normalisation
Conclusion
What is really new in this paper is the GCNN with neighbours node. And the bench show that it have a significant impact on the performance when cross architecture is involved.
For their training they “only” used 16 different project, i’m curious on how having larger range of project maybe with more different purpose may affect the performance because the final embedding have “only” 256 dimensions which i think is small for non supervised learning.
Also i think that’s good that this project produce basic block embedding AND full function embedding, more than in just binary matching all this information can be usefull for automated binary analysis.